How to Solve 3 Common Pitfalls Syncing Duplicate Contacts with HubSpot
Integrating data between systems carries with it many risks, user confusion, and difficulty setting expectations. However, one of the greatest risks comes from data homogenization — or bringing all your data into one common space. Let’s dig deeper.
Imagine you want to integrate Dynamics CRM with HubSpot. You’ve planned all your field mappings and performed limited testing. Your intention is to sync all your field mappings in both directions to keep both systems in sync. Everything seems to be working in good order and timeliness. What could go wrong after this point?
Uniqueness
Each system has its own way of identifying potential duplicate records and managing unique keys. For example, HubSpot requires that each contact has a unique email address. This presents a curious question: what happens when another system does not follow this restriction on unique email address? In most other CRMs, like Dynamics and Salesforce, there are no restrictions on email addresses for contacts or leads. There are ways to set up duplicate detection rules which can help constrain data, but most CRM admins don’t enforce such restrictions, and users tend to create duplicates and messy data in no time.
Timing
Let’s say your integration was enabled and set to operate on all modified records. One day, someone changes a contact record in Dynamics that happens to have the same email address as another contact that already synced to HubSpot. Most integrations will simply update that HubSpot contact with the new CRM contact’s data. This means that your users in HubSpot may see data from one of many different CRM contact records, as well as lead records, depending on which one was the last one in CRM to be modified. As confusing as this can be, it isn’t the most significant potential integration risk.
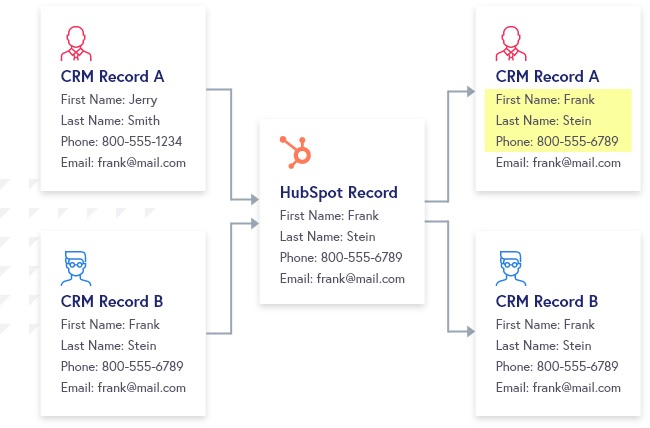
Homogenization
A typical integration syncs data in both directions, so users in each system can see the latest changes and activities where they spend most of their time. What happens when two systems are syncing duplicate records in both directions?
The presence of duplicate CRM records, with all being eligible to sync with HubSpot, results in some CRM data being destructively overwritten. No one has a way of predicting which Dynamics record would “win” the battle, because it all depends on when records were last modified.
Solutions
As you may have learned in this article, there are many careful considerations we must take when planning a bi-directional integration with HubSpot and an external system, like a CRM or ERP. Some of the first questions we ask when scoping such an integration include:
- What objects need to be copied from system A to system B, and vice versa?
- What criteria deems records eligible to sync from each system?
- What fields do you want to copy in each direction for each object?
- Are you aware of any duplicate data you may have in each system? How do you manage duplicates, and how do you want the integration to react to duplicates?
Asking these questions up front, and analyzing the answers together increases our chances for success and high-quality data syncing.
When encountering duplicate data, we recommend:
- Clean up duplicate, outdated, and invalid data as much as possible. Start a policy and training to prevent duplicates and data quality issues in the future, and institute ongoing data hygiene practices.
- Set more restrictive sync criteria for each object involved in the integration. Ideally, this would mean that duplicate records with incomplete data would not be included to sync.
- Add logic that pre-checks the existing data in one system and compares it before depositing data into a given field. This leads to a slower integration, but it can improve the accuracy of individual field mappings.
Final Thoughts
Every integration project we do at LyntonWeb is unique. Your data and processes may vary greatly from the situations discussed. For instance, you may have clean data or conversely, need to improve the quality of yours. No matter what, we’re here to talk about your specific data integration needs.
Read More: Most Common Mistakes To Avoid During a HubSpot Integration